Genetický kód - kód života
Genetický kód - jak skupiny 4 nukleotidů stanovují 20 aminokyselin
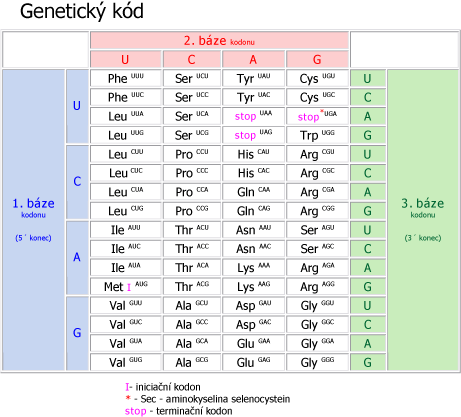
Kód:
- je systém symbolů, které porovnávají informaci jednoho jazyka (sekvence nukleotidů) s informací druhého jazyka (sekvence aminokyselin),
- Morseova abeceda používá symboly tečku a čárku – přesto 2 symboly mohou vyjádřit všechna písmena abecedy pomocí jejich kombinace v různém počtu – např. písmeno C je vyjádřeno jako (-.-.), R (.-.), V (...-), atd.
- mezi každým písmenem se při telegrafování dává malá pauza
Genetický kód:
Jazyk nukleových kyselin je zapsán ve 4 symbolech (4 nukleotidech) – A, T, C, G v molekule DNA a A, U, C, G v molekule RNA. Jazyk proteinů je zapsán pomocí písmen ~ aminokyselin (20 standardních + 1 nestandardní).
Porozumění, jak sekvence bazí v DNA nebo RNA kóduje pořadí aminokyselin v polypeptidovém řetězci, je nezbytné k pochopení různorodosti proteinů.
Jak čtyři nukleotidy kódují 20 aminokyselin?
Čtyři nukleotidy kódují 20 aminokyselin pomocí specifický skupin A, G, C a T (v DNA) nebo A, G, C a U (v RNA).
- Kdyby 1 nukleotid reprezentoval 1 aminokyselinu -> byla by to informace jen pro 4 aminokyseliny.
- Kdyby 2 nukleotidy reprezentoval 1 aminokyselinu -> byla by to informace jen pro 42 = 16 aminokyselin.
- Kdyby 3 nukleotidy reprezentoval 1 aminokyselinu -> byla by to informace jen pro 43 = 64 aminokyselin, tedy více než je všech typů aminokyselin. AVŠAK tyto triplety bazí by nevyžadovaly žádnou "pauzu" mezi sebou pro rozlišení mezi následnými triplety. Tento systém kódování byl nakonec experimentálně potvrzen (F. Crick a S. Brenner dokázali v roce 1955).
Každý nukleotidový triplet byl nazván kodon. Každý kodon specifikuje jednu aminokyselinu. Např. kodon AGU kóduje serin, GCA alanin a CUU leucin. Protože kód se využívá až v průběhu translace, je genetický kód zaspán v "dialektu" RNA (pomocí nukleotidů A, G, C a U). Každý nukleotid je částí právě jednoho kodonu.
Genetický kód byl rozluštěn až v roce 1966, kdy ke každému kodonu byla přiřazena právě 1 aminokyselina.
Čtení genetického kódu - nepřekrývající kodony jsou zasazeny do čtecího rámce
Genetický kód se čte na ribozomech při procesu translace, kdy se jednosměrně rozeznávají kodony mRNA a antikodony tRNA, a kdy se přechodně spojí na základě komplementarity a kdy každá tRNA nese připojenou aminokyselinu.
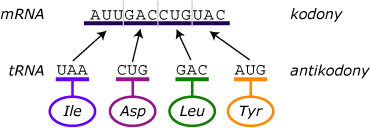
Genetický kód je čten po tripletech. Je však nutné stanovit počátek čtení – který nukleotid je ten první? Jeden způsob čtení tripletů je založen na stanovení pevného začátku čtení – čtecí rámec. Začíná startovacím nukleotidem, čímž je zajištěno, že kodony budou čteny správně.
Čtecí rámec:
- otevřený čtecí rámec – je ohraničen specifickými kodony, které nekódují aminokyseliny (iniciační a terminační kodon); typické pro geny kódující dlouhé funkční proteiny,
- uzavřený čtecí rámec – je přerušován více terminačními kodony a tedy nemůže kódovat dlouhé a souvislé polypeptidové řetězce (nejde o geny).
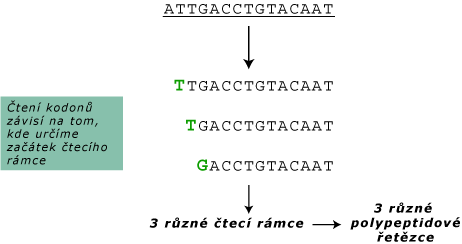
Mutace může modifikovat informaci zakódovanou v sekvenci nukleotidů:
- posunová mutace – inzerce nebo delece nukleotidů, které mění genetickou instrukci pro tvorbu polypeptidu změnou čtecího rámce,
- mutace měnící smysl kodonu – mění kodon pro jednu aminokyselinu na kodon pro jinou aminokyselinu (UUC - fenylalanin > UUA – leucin),
- mutace beze smyslu (nesmyslná mutace) – mění kodon pro aminokyselinu na stop kodon (UAC – tyrosin > UAA – stop kodon).
Vlastnosti genetického kódu
Genetický kód je úplný, nezkrácený slovník přiřazující 4 písmena jazyka nukleových kyselin 20-ti písmenům jazyka proteinů. Následující seznam sumarizuje hlavní vlastnosti genetického kódu:¨
- genetický kód je tripletový (1 kodon ~ triplet = 3 nukleotidy) a každý z tripletových kodonů specifikuje jednu aminokyselinu,
- ukazuje sekvenci ve směru 5´> 3´ tří po sobě následujících nukleotidů v mRNA (1. nukleotid kodonu je na 5´ konci),
- kodony jsou nepřekrývající a každý nukleotid je částí právě jednoho kodonu,
- skládá se z 64 kombinací kodonů,
- většina aminokyselin je specifikována více než jedním kodonem > genetický kód je degenerovaný,
- většina kodonů je synonymních – navzájem odlišné kodony různého smyslu, dávají stejný smysl, (např. kodony pro leucin – CUU, CUC, CUG, CUA, UUA a UUG),
- zahrnuje tři stop kodony: UAA, UAG a UGA; tyto kodony nekódují aminokyselinu a ukončují translaci,
- kodon UGA je bifunkční – je stop kodonem, ale zároveň může kódovat 21. standardní aminokyselinu selenocystein (u prokaryot i u obratlovců),
- při čtení transkriptu genu (při skenování řetězce mRNA) se začíná od startovacího nukleotidu, kterým začíná čtecí rámec,
- kodon AUG kóduje aminokyselinu methionin, ale zároveň v určitém kontextu slouží jako iniciační kodon, který označuje přesné místo v sekvenci mRNA, kde začíná kód pro konkrétní polypeptid (je bifunkční); pozice iniciačního kodonu specifikuje čtecí rámec pro zbytek sekvence určením, jaké nukleotidy se seskupí do tripletů,
- většinu kodonů lze rozdělit do kodonových rodin (4 synonymní kodony, které se liší 3. nukleotidem - např. leucin má kodonovou rodinu CUU, CUC, CUG, CUA; kodonových rodin je celkem 8) a do dvoukodonových sad (2 synonymní kodony končí ve 3. pozici jeden na A a druhý na G, nebo jeden na U a druhý na C),
- většina kodonů je univerzální – u všech žijících organizmů má stejný smysl (jsou však výjimky); hovoříme o standardním kódu a je to také důkaz evoluce života po několik miliard let.