
![]()
Genetická informace
Genetická informace (GI) je informace primárně obsažená v nukleotidové sekvenci pomocí čtyř deoxyribonukleotidů v DNA řetězcích (A, T, G, C) nebo čtyř ribonukleotidů v RNA řetězcích (A, U, G, C), která se dědí. Genetická informace je informací o primární struktuře peptidů (v DNA a RNA sekvenci), DNA (v RNA sekvenci) nebo tRNA, rRNA (v DNA sekvenci).
Způsob přenosu genetické informace
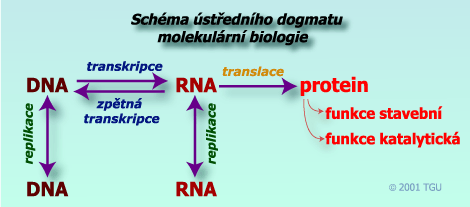
Přenos genetické informace je souhrnně zobrazen v ústředním dogmatu molekulární biologie, kde je možný přenos GI z nukleové kyseliny do nukleové kyseliny, nebo z nukleové kyseliny do proteinu. Dosud se předpokládá, že není možný přenos GI z proteinu do nukleové kyseliny nebo z proteinu do proteinu.
Genetický kód
Na ribozomech dochází k překladu genetické informace ze sekvence nukleotidů nukleových kyselin do sekvence aminokyselin proteinů. Tato informace je zakódována, kdy jedna aminokyselina je kódována trojicí (tripletem) nukleotidů a tento kodon je základní jednotkou genetického kódu.
Princip čtení genetického kódu je podstatou translace a spočívá v jednosměrném a specifickém rozeznávání kodonů v mRNA antikodony tRNA nesoucí aminokyselinu na základě komplementarity bazí. Čtení genetického kódu se děje po tripletech.
2. báze kodonu |
|||||||
| U | C | A | G | ||||
1. báze kodonu (5´ konec) |
U | Phe UUU |
Ser UCU |
Tyr UAU |
Cys UGU |
U | 3. báze kodonu (3´ konec) |
Phe UUC |
Ser UCC |
Tyr UAC |
Cys UGC |
C | |||
Leu UUA |
Ser UCA |
stop UAA |
stop*UGA |
A | |||
Leu UUG |
Ser UCG |
stop UAG |
Trp UGG |
G | |||
| C | Leu CUU |
Pro CCU |
His CAU |
Arg CGU |
U | ||
Leu CUC |
Pro CCC |
His CAC |
Arg CGC |
C | |||
Leu CUA |
Pro CCA |
Gln CAA |
Arg CGA |
A | |||
Leu CUG |
Pro CCG |
Gln CAG |
Arg CGG |
G | |||
| A | Ile AUU |
Thr ACU |
Asn AAU |
Ser AGU |
U | ||
Ile AUC |
Thr ACC |
Asn AAC |
Ser AGC |
C | |||
Ile AUA |
Thr ACA |
Lys AAA |
Arg AGA |
A | |||
Met I AUG |
Thr ACG |
Lys AAG |
Arg AGG |
G | |||
| G | Val GUU |
Ala GCU |
Asp GAU |
Gly GGU |
U | ||
Val GUC |
Ala GCC |
Asp GAC |
Gly GGC |
C | |||
Val GUA |
Ala GCA |
Glu GAA |
Gly GGA |
A | |||
Val GUG |
Ala GCG |
Glu GAG |
Gly GGG |
G | |||
I - iniciační kodon * - Sec - aminokyselina selenocystein stop - terminační kodon |
Genetický kód k vytištění (pdf)
Vlastnosti genetického kódu
- Genetický kód je tripletový (třínukleotidový); jedna aminokyselina je kódována trojicí nukleotidů v nukleové kyselině (tripletem).
- Skládá se ze 64 kodonů.
- Je degenerovaný, nadbytečný; 1 aminokyselina může být kódována několika různými kodony.
- Aminokyseliny kóduje 61 kodonů (kodony se smyslem).
- Většina kodonů je synonymních, kdy různé kodony mají stejný smysl (kódují jednu aminokyselin).
- Kodony se stejným smyslem se rozdělují do 8-mi kodonových rodin (4 synonymní kodony lišící se 3. nukleotidem) a 5 dvoukodonových sad (dva synonymní kodony končící třetím nukleotidem jednoho na A a druhého na G nebo jeden na U a druhý na C.
- Je nepřekrývající se. Záleží, na kterém nukleotidu začne překlad. Posun čtecího rámce vede ke změně smyslu informace sekvence aminokyselin v proteinu.
- Některé kodony jsou nesmyslné, které nekódují žádnou aminokyselinu a mají funkci terminace translace: UAA (ochre), UAG (amber).
- Kodon UGA (opal) je bifunkční, má funkci terminace translace a také kóduje aminokyselinu selenocystein, který má svou vlastní tRNA.
- Kodon AUG je bifunkční: kóduje metionin nebo signalizuje začátek translace (iniciační kodon).
- Většina kodonů je univerzálních, takže mají stejný smysl u všech živých soustav (standardní genetický kód).
- Genetický kód podléhá evoluci.
|
![]()
![]()
![]()